
 Daniel Carter
Daniel Carter
Vibe coding has gone from a niche developer trend to a mainstream way of building websites in under two years. Tools like Lovable, Bolt.new, v0 and Replit let people describe a site in plain English and get working code back. Lovable hit $20m ARR in two months, the fastest in European startup history, and over 25 million projects have been built on the platform. The output looks polished, the deployment is one click, and the cost is a fraction of hiring a developer.
The catch is that almost none of these tools produce SEO friendly websites by default.
This isn't a marketing-speak claim. It's a structural issue baked into how the most popular vibe coding platforms generate code. If you've launched a Lovable site and noticed Google Search Console showing the homepage as essentially empty, or you've shared a link on LinkedIn and watched it render as a blank preview card, you've already met the problem.
This article walks through exactly what vibe coding tools produce, why their default output struggles in search, what Google actually does with JavaScript, why AI crawlers make the situation worse, and the practical fixes available, both for sites already built and for new projects. There are concrete prompts at the end you can use with Claude Code or Cursor to build a properly indexed site from the outset.
What vibe coding tools actually produce

Most articles on this topic skip the technical reality of what these tools generate. That's the wrong place to start. To understand the SEO problem you have to understand the architecture.
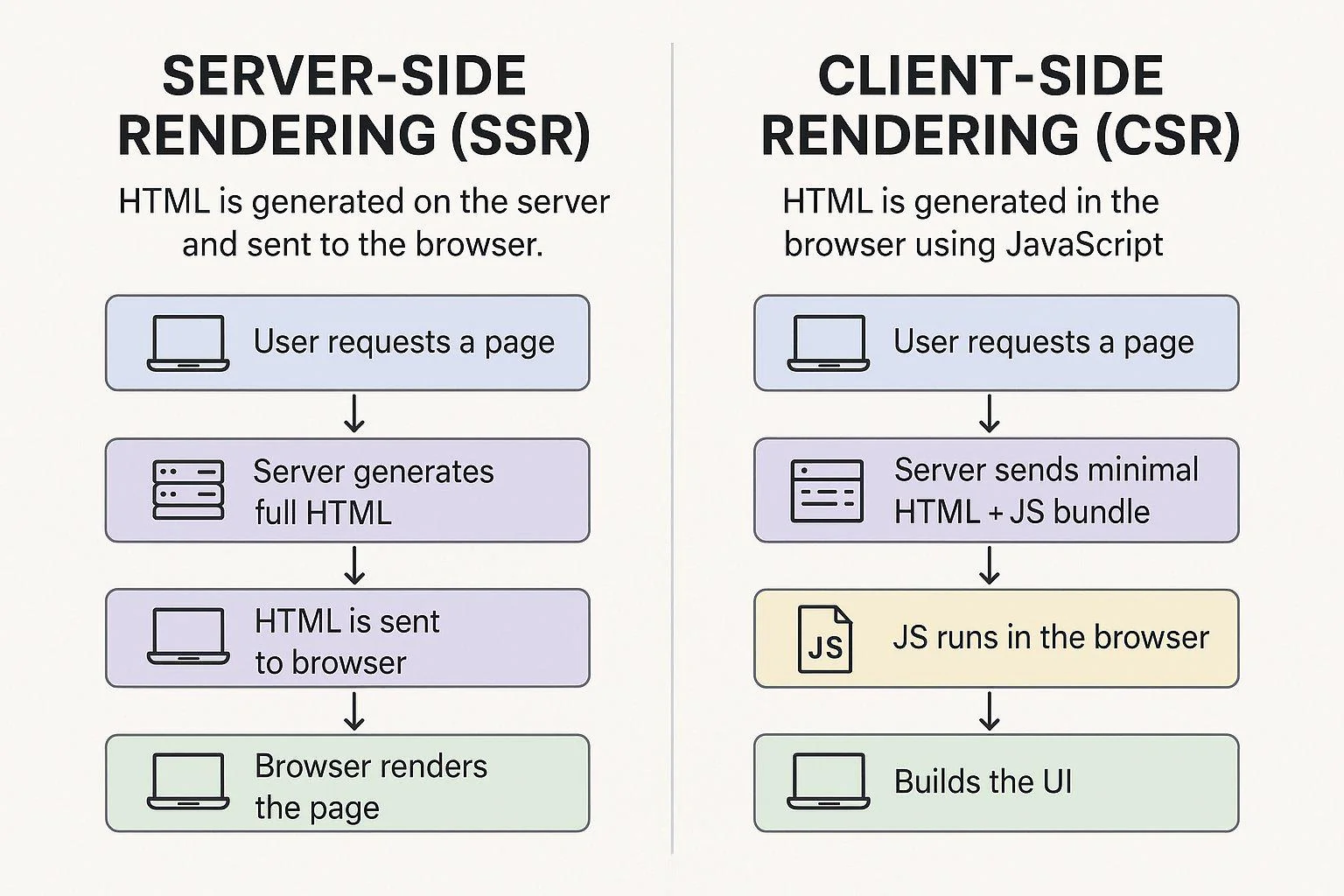
Lovable generates a React + TypeScript application built with Vite, styled with Tailwind CSS, and uses shadcn/ui components. The default deployment is a client-side rendered single page application (SPA). Lovable Cloud or Supabase handles the backend. The frontend is shipped as a static index.html containing a near-empty <div id="root"></div> plus a JavaScript bundle that boots the app in the browser.
Bolt.new is more flexible. It supports React, Next.js, Svelte, Vue, Astro and several other frameworks via StackBlitz's WebContainer environment. The default output for a "build me a website" prompt skews towards client-rendered React or Vite apps unless you explicitly ask for Next.js or another SSR-capable framework.
v0 by Vercel produces React components and full pages styled with Tailwind, intended for integration into a Next.js project. When v0 outputs a complete site it leans toward Next.js, which is SEO-friendly by default. When users copy components into a plain Vite/React shell, the SEO benefits of Next.js are lost.
Replit spans everything from static HTML to full-stack apps, but its AI Agent commonly scaffolds React or Next.js projects.
The point that matters: when a non-technical user types "build me a SaaS landing page" into Lovable or Bolt without specifying the rendering model, the most likely output is a client-side rendered React SPA. That's a Vite-built bundle that loads in the browser and assembles the page after JavaScript executes.
The shell problem: what search engines see on a CSR site
A client-side rendered React app delivers the same minimal HTML to every visitor on the first request. The HTML payload looks roughly like this:
html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Site</title>
<meta name="viewport" content="width=device-width, initial-scale=1" />
</head>
<body>
<div id="root"></div>
<script type="module" src="/assets/index-abc123.js"></script>
</body>
</html>That's the shell. There are no headings, no body copy, no internal links, no schema, no Open Graph tags worth mentioning. Everything that humans see on the page is constructed in the browser after the JavaScript bundle downloads, parses, executes, fetches data, and mounts the React component tree into that empty <div>.
A human visitor doesn't notice this because their browser is fast enough to make it invisible. A crawler that doesn't run JavaScript sees the shell and nothing else. A crawler that does run JavaScript has to allocate the time and compute to render the page, and that has consequences explored in the next section.
The first practical test is the one anyone can do: right-click any vibe coded site, select "View Page Source", and search for any sentence visible on the page. If the text isn't in the source, your content lives entirely behind JavaScript. Compare that to viewing the source of a Next.js or WordPress site, where the body copy is right there in the HTML.
Yes, Google renders JavaScript. That doesn't make CSR sites SEO friendly
The most common pushback on the "SPAs are bad for SEO" argument is that Google has rendered JavaScript for years. That's true. Googlebot uses an evergreen Chromium-based Web Rendering Service that can execute modern JavaScript and index the rendered DOM. The problem is that rendering at scale is expensive and introduces a layered set of failures that don't exist on server-rendered sites.
I've created various sites using LOVABLE - and despite using PRE-RENDER (prerender.io) Google could not properly index the website - what it did index was often malformed or missing information - renders in URL inspection would often be blank. I would often get other issues such as random URL generation, even if I specific canonicals - primarily because of the LOVABLE configuration, CANONICALS, like meta data would be injected in, this meant if Googlebot requested the URL and the initial shell was presented without the meta it would mean the canonical wouldn't be picked up.
When I looked at pre-render cache and render history - it became apparent this was going to be an issue:
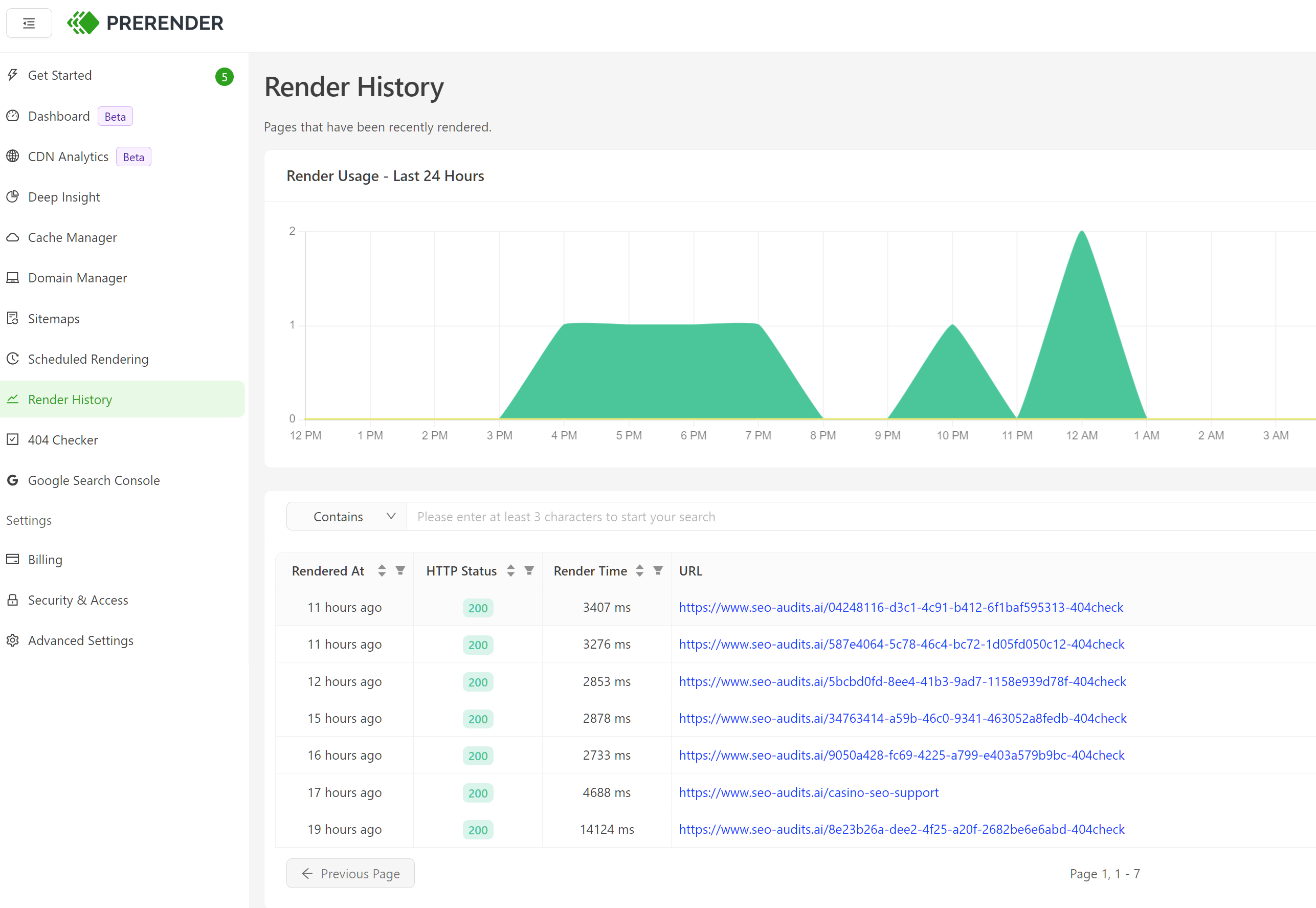
And subsequently, I had TERRILE indexing performance - the website had around 50 URLS, over a 3 month testing window 9 URLS got indexed, all of which had the same meta data.
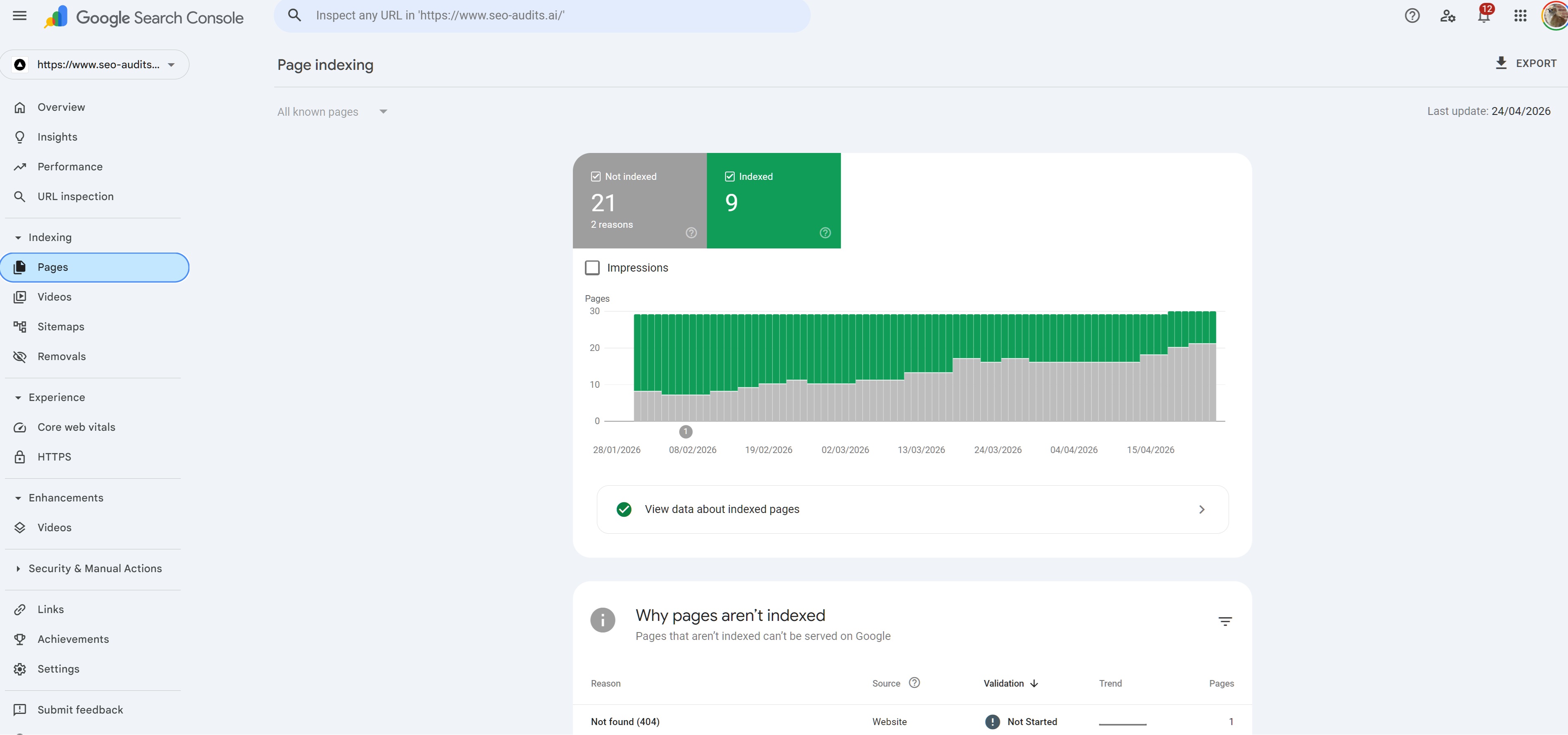
So why is this such an issue in 2026?
Two-wave indexing.
Google processes JavaScript pages in two passes. The first wave indexes the raw HTML. The second wave queues the page for rendering, executes JavaScript, and then indexes the rendered output. Vercel's research on 37,000+ matched server-beacon pairs found the 25th percentile of pages were rendered within 4 seconds of the initial crawl, which is faster than the older "rendering takes weeks" narrative suggested. But that data was gathered on a high-authority Next.js site (nextjs.org) with proper rendering signals.
For lower-authority sites, the picture is worse. Onely's research has consistently found that around 32% of JavaScript-dependent content remains unindexed a month after the URL was first discovered. Even where rendering succeeds, the median delay between URL discovery and content indexing has been measured in days for many sites, not seconds.
This MAY have been designed this way on purpose - why? because it helps to nullify programmattic SEO spam at the outset (you know the people who are using tools and automations to mass produce AI content and dump it on domains at scale).
Crawl budget consumption.
Rendering a page is roughly 9x more resource-intensive for Google than parsing static HTML. On a vibe coded SPA, every page Google wants to index has to go through the rendering pipeline. On large sites this eats crawl budget and slows discovery of new pages. Google's official documentation has, for several years, recommended server-side or static rendering for content that needs to be indexed reliably. The two-wave approach is described as a fallback, not the recommended path.
Internal links generated by JavaScript.
Many React apps use programmatic navigation (e.g. onClick={() => navigate('/about')}) rather than proper <a href="/about"> anchor tags. Crawlers discover URLs through links in the HTML. If your nav is JavaScript-driven without real href attributes, the first wave crawl finds zero internal links and the discovery of subpages is delayed until rendering happens, if it happens at all.
Rendering failures.
A single JavaScript error, a slow API call, a missing dependency on a CDN, or a script that hangs on useEffect can all cause Google's renderer to time out before the content arrives. The page gets indexed as blank. Whether you noticed this is what Search Console's URL Inspection tool, "View Crawled Page" feature, is designed to show you.
The summary is that Google can render your CSR site, but it's slower, less reliable, more resource intensive, and prone to specific failure modes that don't apply to server-rendered HTML. For a marketing site, blog, or e-commerce store where organic traffic matters, that's enough downside to avoid CSR by default.
The bigger issue in 2026: AI crawlers don't render JavaScript at all
This is the part of the conversation that has changed dramatically over the last 18 months and is mostly absent from older articles.
GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, Meta-ExternalAgent, and most other AI crawlers do not execute JavaScript. They fetch the raw HTML response, parse it, and move on. Vercel's analysis of crawler behaviour, and supporting data from Prerender.io covering hundreds of millions of bot requests, found no evidence of JavaScript execution by these agents. OpenAI's own documentation for the ChatGPT browsing tool describes a simplified text extraction process rather than full DOM rendering. Perplexity's help docs confirm HTML snapshot retrieval without JS execution. Anthropic's Claude crawler operates on text-based parsing.

If your vibe coded site is a Vite/React shell, every AI crawler currently sees an empty page. The product descriptions, pricing tables, FAQ content, comparison data, and case studies on your site exist only after the JavaScript runs in a real browser, which means they're invisible to ChatGPT, Claude, Perplexity, and the AI search systems that increasingly drive product discovery and citations.
This creates a split visibility problem. A vibe coded site might rank acceptably on Google after the rendering queue catches up, while being completely absent from AI-generated answers. As AI search routes more research and purchase intent through ChatGPT, Perplexity, and Google's AI Overviews, that gap is no longer a rounding error.
Google's AI Overviews and Gemini benefit from Google's existing rendering infrastructure, so the issue there is closer to the standard JavaScript SEO concerns. For everything outside Google's stack, the practical position is that JavaScript-dependent content doesn't exist.
Specific pitfalls of vibe coded sites
Beyond the rendering model, the way vibe coding tools structure projects creates several SEO problems that don't exist on traditional CMS-built sites.
No CMS by default.
Lovable, Bolt and v0 don't generate a content management layer for marketing pages out of the box. Body copy, headings, and metadata are hardcoded into React components. Updating a title tag or rewriting a paragraph means re-prompting the AI or editing the code, which is a poor workflow for ongoing SEO work where you're regularly refining titles, meta descriptions, and content for ranking improvements.
Title tags and canonicals are not per-page by default.
A standard CSR React app has a single <title> and a single set of meta tags in index.html. Every route shows the same title in the source code. Tools like react-helmet or react-helmet-async let you set per-route titles via JavaScript, but those updates only happen after the bundle executes. The raw HTML still shows the default title, which is what AI crawlers and the first-wave Google index sees.
No sitemap, no robots.txt.
Lovable and Bolt don't generate a sitemap by default. Without a sitemap, Google has to discover URLs through links, which is harder when the links are constructed by JavaScript.
Open Graph and Twitter Card previews break.
This is the most visible failure to non-technical users. Sharing a Lovable site link on LinkedIn, Slack, X, or in iMessage usually shows a blank preview or generic site-wide metadata, not the page-specific image and description. The reason is that LinkedIn, X, Facebook and similar services do not execute JavaScript when fetching link previews. They read the raw HTML, find no Open Graph tags specific to the page, and render whatever is in the static index.html (or nothing at all). Even react-helmet-async, which works for Google because Google eventually renders, doesn't fix social previews because social platforms read the raw response.
Schema markup absent or incorrect.
Vibe coding tools rarely add structured data (JSON-LD) to outputs unless explicitly prompted. When they do, it's often added via JavaScript and lives in the rendered DOM rather than the raw HTML. Google's structured data testing tools rely on what's in the served HTML or rendered output, but third-party AI systems extracting facts from your pages need the data in the static response.
Internal linking via JavaScript handlers. As mentioned above, React apps often use useNavigate() or Link components without proper href attributes. Even where Link does produce a real <a> tag, the destinations are still client-side routes that depend on JavaScript to render the target page's content.
Hydration mismatches and partial rendering. When developers do try to bolt SSR onto an existing CSR vibe coded project, they frequently introduce hydration errors where the server-rendered HTML doesn't match what the client expects. The result is content flicker, broken interactivity, or worse, the server output is correct but client-side JavaScript overwrites it with something that wasn't there during the initial render.
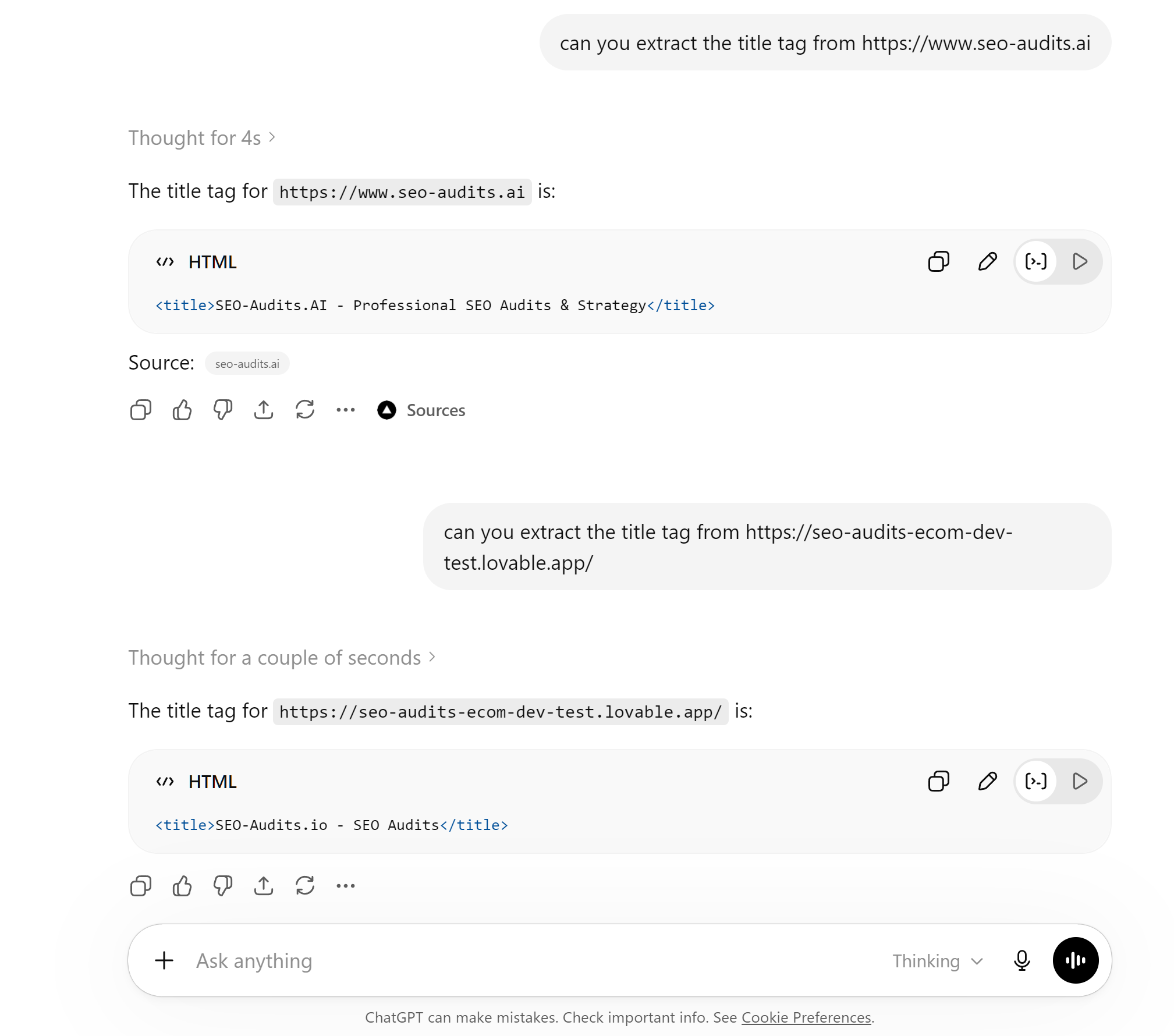
I tessted this numerous times with numerous different solutions - so, here, I moved the main www.seo-audits.ai website onto Vercel / NEXT.JS with SSR, so chatGPT was able to pull the title, but, on the original LOVABLE DEV URL provided once you pull the domain away, the same page, same content and the output was wrong, AI fabricates data if it cannot get the data you request - I tested this numerous times with LOCKED PDFS where AI, if it couldn't access it, would fabricate what it saw (it saw nothing) - the same happens with websites!
Workarounds for sites already built with Lovable, Bolt or similar
If you've already built a site and don't want to start over, there are graduated options ranging from cheap and partial to expensive and complete.
1. Add react-helmet-async and proper metadata
Lovable specifically supports installing react-helmet-async for per-page titles, descriptions, canonicals and Open Graph tags. This addresses the metadata problem for Google (which renders) but not for AI crawlers or social platforms (which don't). It's a useful first step but it doesn't solve the underlying CSR issue. You can prompt Lovable with: "Install react-helmet-async and set unique titles, descriptions, canonical URLs, and Open Graph tags for every route."
2. Static Site Generation (SSG) at build time
Tools like vite-ssg or vite-plugin-ssr pre-render every route to a static HTML file at build time. The build process spins up a headless browser, visits each route in your app, captures the rendered HTML, and writes it to disk as a static file. The deployed site serves real HTML on first request, then hydrates into the React app for client-side interactivity. This works well for sites with predictable routes and content that doesn't change per user. It solves the CSR problem comprehensively for Google, AI crawlers, and social previews. The implementation requires a custom entry-server.tsx, a build script that uses renderToString and StaticRouter, and configuration of your hosting platform (Netlify, Vercel) to serve the static files. Several developers have published working setups for Lovable specifically, though it's a non-trivial migration.
3. Prerender.io (dynamic rendering)
Prerender.io intercepts requests, detects whether the user agent is a bot, and serves a pre-rendered static HTML version to bots while regular users get the JavaScript-powered site. The service handles the headless rendering and caching. It currently supports detection of GPTBot, ClaudeBot, PerplexityBot, and other AI agents in addition to traditional search bots. Plans start around $49/month for 25,000 renders. The trade-offs: it's an ongoing cost, you're dependent on a third party, and Google has explicitly de-emphasised dynamic rendering as a long-term solution in favour of SSR or SSG. Google still accepts dynamic rendering, and it's not cloaking when implemented correctly (the same content is served to users and bots, just via different rendering paths), but the official guidance points elsewhere. Rendertron, the open-source equivalent that Google itself used to maintain, was archived and deprecated in 2022. Prerender.io is the realistic option in this category.
4. Migrate to Next.js
The cleanest fix is to move from Vite/React to Next.js. The codebase looks similar, the React components are largely portable, and you gain SSR, SSG, ISR, and the Metadata API in one move. Lovable's React + Supabase output is more migratable than most people expect because the components are standard React. Realistic time investment for a marketing site is in the 40 to 80 developer hours range, depending on how many routes and how much custom logic exists. Cursor or Claude Code can handle most of the migration if you give it the existing repo and ask for a Next.js App Router rewrite with the same routing structure.
The right choice depends on what's already built and the cost of switching. For a small marketing site with five to ten pages, SSG with vite-ssg or migrating to Next.js are both reasonable. For a larger app where the SPA architecture is already deep, Prerender.io is the path of least resistance even with the ongoing cost.
Vibe coding an SEO friendly site from the outset
The cheapest fix for any of the above is to not create the problem in the first place. If you're starting a project today and SEO matters, the right approach is to specify your rendering model up front and use a tool that respects it.
Choose Next.js, not Vite/React. Next.js with the App Router is server-rendered by default. Components are React Server Components unless you explicitly mark them with "use client". Pages are rendered on the server (SSR), at build time (SSG), or revalidated on a schedule (ISR). The output sent on the first request is real HTML with content, headings, links, and metadata in place. This eliminates the entire CSR problem at the framework level.
Use the right tool for the job. Lovable's default output is Vite/React. If SEO matters, vibe coding with Lovable is the wrong starting point unless you commit to converting it. Bolt and v0 both support Next.js explicitly. The cleanest workflow for an SEO-driven build is:
Use Cursor or Claude Code with a Next.js scaffold from day one
Use v0 for individual UI components that you paste into the Next.js project
Use Lovable only for prototypes or apps where organic search isn't the channel
Connect a CMS from the beginning. If the site has any content that will change without you wanting to redeploy code, connect a headless CMS (Sanity, Payload, Contentful, Strapi, or even WordPress in headless mode) at the start. Next.js's data fetching makes this straightforward. The CMS owns the content, the framework owns the rendering. You can then update titles, meta descriptions, body copy, and schema without touching code, which is what an SEO workflow actually needs.
Use the Metadata API. Next.js 13+ ships with a generateMetadata function that produces per-page titles, descriptions, canonical URLs, Open Graph tags, and Twitter Cards from data, including data fetched from your CMS. This handles every metadata concern raised earlier in one mechanism, with the output present in the HTML on the first request.
Add a sitemap and robots.txt at build. Next.js supports both as first-class citizens (app/sitemap.ts, app/robots.ts). Generate them automatically from your routes or your CMS data.
Use real anchor tags. The <Link> component in Next.js produces real <a href> tags by default. Use it for all internal navigation. Avoid onClick handlers that call router.push() for primary navigation links.
Example prompts for Claude Code or Cursor
The following prompts produce SEO-ready Next.js scaffolds. They're written to be specific about rendering, metadata, and structure, which is the part most people skip when prompting AI tools.
Initial scaffold prompt:
Build a Next.js 15 marketing site using the App Router. All pages must be server-rendered or statically generated. No client-side rendering for content pages. Use TypeScript and Tailwind CSS. The project should include the following from the start:
A root layout with default metadata
A
generateMetadatafunction on every page that sets a unique title, meta description, canonical URL, Open Graph tags (og:title, og:description, og:image, og:url, og:type) and Twitter Card tags (twitter:card, twitter:title, twitter:description, twitter:image)An
app/sitemap.tsfile that generates an XML sitemap from the route listAn
app/robots.tsfile that produces a robots.txt allowing crawling and pointing to the sitemapReal
<Link>components with proper href attributes for all internal navigationJSON-LD structured data injected server-side using a
<Script type="application/ld+json">tag in the head, with appropriate Schema.org types per page (Organization for the homepage, Service for service pages, Article for blog posts)A 404 page and a 500 error page
Image components using Next.js
<Image>with width, height, and descriptive alt textProper heading hierarchy, exactly one
<h1>per pageThe pages I need are: [list your pages]. For each page, suggest a draft title, meta description, and H1.
Connecting a CMS:
Connect this Next.js project to a Sanity CMS instance. Define a
Pageschema with fields for title, slug, meta description, canonical URL override, Open Graph image, body content (Portable Text), and structured data type. UpdategenerateMetadataon dynamic routes to fetch metadata from Sanity. UsegenerateStaticParamsso all pages are statically generated at build time, withrevalidateset to 60 seconds for incremental regeneration.
Auditing an existing vibe coded site:
Here is the codebase for a Vite + React SPA generated by Lovable. Audit it for SEO issues. Specifically, check whether content is present in the raw HTML or only in the rendered DOM, list every
<title>and meta tag and where they are set, identify whether routing produces real<a href>tags or relies on JavaScript handlers, and list all components that fetch data viauseEffectrather than during initial render. Then propose a migration plan to Next.js App Router that preserves the existing component structure and styling.
These prompts are written for engineering quality of output. The prompt-to-app tools are most useful when given specific constraints. A vague prompt produces a vague site.
The verdict
Vibe coded websites can be SEO friendly. The default output from the most popular vibe coding tools is not. The gap between those two statements is where most of the trouble happens.
The two questions worth answering before starting any vibe coded project are:
Is organic search a meaningful channel for this project? If the project is an internal tool, an MVP shown to investors, a paid-acquisition-only product, or a niche app where users arrive via direct links, the SEO concerns matter much less. Lovable and Bolt are perfectly fine for that work.
If organic search matters, am I willing to specify the rendering model up front? A Next.js App Router site, prompted properly, with metadata, sitemaps, structured data, and a CMS in place from day one, is faster to build with vibe coding tools than it ever was by hand. The technology hasn't taken anything away from SEO. It's only made the cost of getting it wrong cheaper, faster, and easier to ignore until traffic doesn't show up.
For sites already built on Lovable or similar with the wrong default, the order of fixes is roughly: install react-helmet-async for metadata, add SSG via vite-ssg if the site is small, deploy Prerender.io if you need a quick fix without rearchitecting, and migrate to Next.js if SEO is a long-term channel and the site is going to keep growing. The longer you delay the migration, the more components you'll have to port. The earlier you commit to SSR or SSG, the less it costs.
The framing that often gets pushed by tool vendors, that Google handles JavaScript fine and SEO concerns are overblown, is not aligned with what Google's own documentation says, what the rendering data shows, or what AI crawlers actually do. CSR is a legitimate architecture for applications. It's the wrong architecture for content that needs to be discovered.